This post is working from the following assumptions:
- The Cradlepoint devices are using Cradlepoint’s cloud management service. Otherwise the routing between the Cradlepoint and the protected network needs to be set up. I was unable to get this to work, though I didn’t put any time in to it since I didn’t have to get it to work.
- A pseudo “Spoke-Hub” setup, with the redundancy of the hub to the spoke not being of great concern. In this case our hub site is a cloud provider that uses Fortinet’s hosted version of a Fortigate.
- I am not an expert in this field, some of these steps may not be needed or the configuration suboptimal in some ways. I am just relating what worked for me.
The initial setup of the spoke site is a simple site-to-site VPN utilizing static IP addresses at each site:
That link will need to be redone since the new connection at the spoke site will need to be an aggregate VPN and the existing IPsec tunnel cannot be set as an aggregate member. I recommend using the USB configuration load so that if the process goes south, the Fortigate can be rebooted and the old, working configuration reloaded.
First, the Cradlepoint needs to be set to a dedicated interface on the Fortigate. For most of the sites I used Wan2, though at one I had to take a port out of the Lan configuration. Optimally this port will be part of a separate network so that a system can be hooked to other ports in the set for diagnosing subnet specific issues, but, I forget to do that every time. With that set, I set two equally weighted static routes to the static IP address of the Hub, one through the existing gateway, and one through the internal address of the Cradlepoint. (I did this because the only thing I wanted routed over the Cradlepoint was work traffic.)
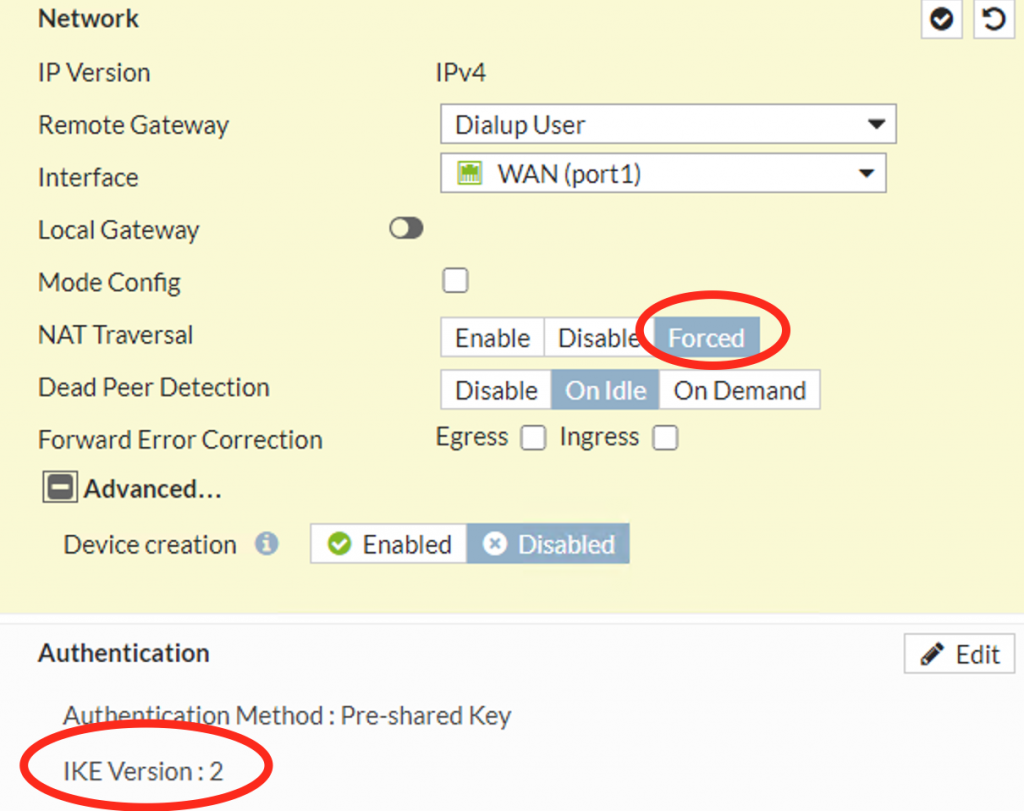
Next, make a new VPN connection at the Hub that will listen for the Spoke connection. This will be a “dial up” VPN connection; I used IKE2 and Forced NAT transversal based on recommendations from Fortinet’s support forum:
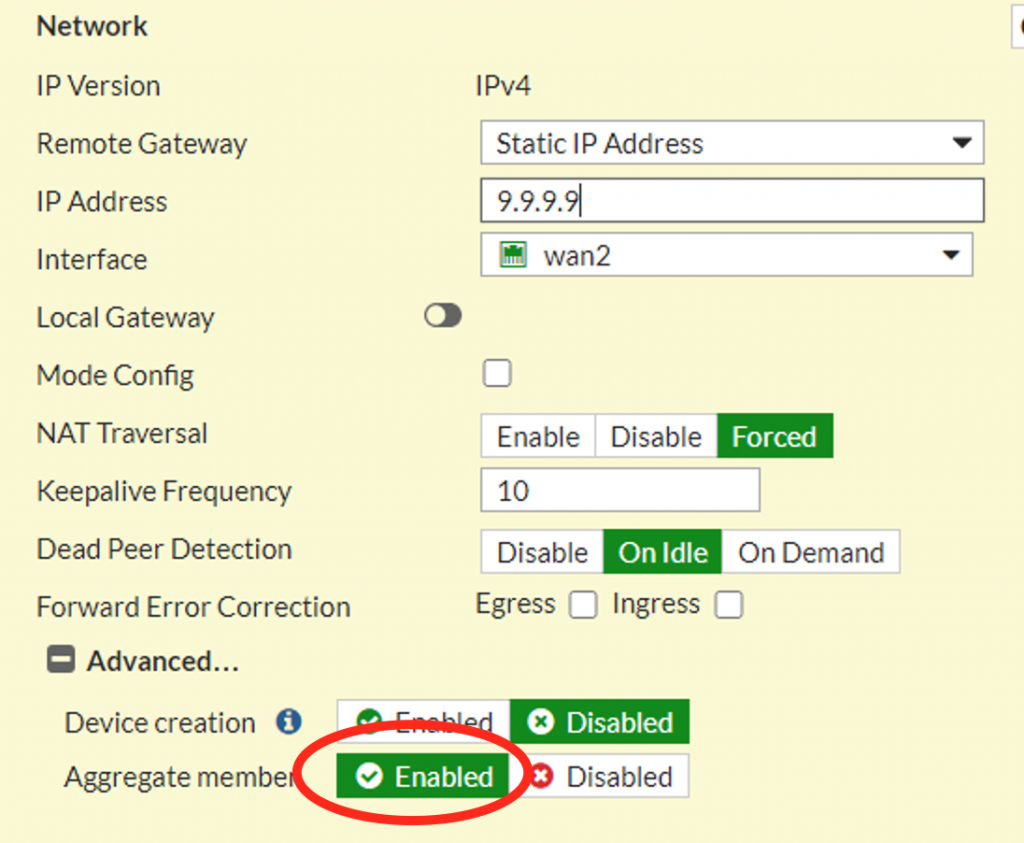
The at the spoke site I then setup a matching VPN connection, being careful to mark as an aggregate member:
Next, setup a new Redundant IPsec aggregate on the Spoke and add the new VPN connection to it. On the Hub site add a new, equally weighted, static route to the Spoke’s network using the new VPN connection made at the hub and add policy rules allowing traffic over it.
So far this has been non-destructive, but the next step will interrupt the connection for a bit, depending on how fast you are. On the spoke, change the default gateway to the hub network from the existing VPN connection to the IPsec aggregate, and then change the policy rules used to allow traffic to (and from) the hub to use the IPsec aggregate as well. At this point, the VPN connection over the Cradlepoint network should come up, if not diagnose and fix the issue (every time I had an issue here it was because my settings in the VPN connections did not match up).
Next, delete the old VPN connection on the Spoke system that went to the Hub network and recreate it, this time as an aggregate connection.
In this next step I usually add the new, re-done, VPN connection to the aggregate and then remove the Cradlepoint aggregate to more throughly test the connection. Once I confirm that it works I add the Cradlepoint back into the aggregate. I then test the redundancy by “breaking” the regular VPN connection at the hub (by changing the passcode, etc.) and the Fortigate should fail-over to the Cradlepoint VPN. When I “un-break” it, it should fail-back (confirm by resetting the statistics on the VPN monitor).